빅데이터란?
RAM에 따라 0~64GB 규모의 Local컴퓨터에 저장할 수 있는 데이터이다. 그러나 필요한 데이터가 증가하고 32GB 나아가 64GB보다 큰 데이터들을 저장의 필요성이 대두됨에 따라, SQL Database, 분산 시스템이 나타났다.
로컬시스템은 단일 계산 시스템으로 컴퓨터 1대 라고 생각하면 된다.
분산시스템은 네트워크를 통해 연결된 컴퓨터 여러대라 생각하면 된다.
데이터를 저장할 때 특정 용량 이후에는 cpu가 높은 local 시스템으로 확장하는 것 보다 cpu가 낮은 여러 시스템으로 확장하는것이 더 쉽기에 빅데이터를 관리하는 시스템들은 주로 분산시스템 방식을 채택한다.
분산시스템의 장점은 결함 감내 시스템(Fault tolerant system)도 있는데 , 이 시스템 덕분에 하나의 시스템에 장애가 발생하더라도 전체의 네트워크는 계속 작동이 가능하다.
**
결함 감내 시스템
시스템을 구성하는 부품의 일부에서 결함(fault) 또는 고장(failure)이 발생하여도 정상적 혹은 부분적으로 기능을 수행할 수 있는 시스템이다. 출처
Hadoop?
하둡은 매우 큰 파일을 여러 시스템(저장소)에 배포하는 기술이다. HDFS(Hadoop Distribute File System)을 사용한다. 하둡의 장점은 크게 4가지로 나뉠 수 있는데
1. 대용량 데이터 저장
2. 스트리밍 방식
- 속도보단 양에 집중한다.
3. 범용 하드웨어 사용
- 결함 감내 시스템을 사용하기에 특별히 안정성 있는 하드웨어를 사용하지 않아도 된다.
4. 파일 블록으로 저장
4. 파일 블록으로 저장
결함 감내 시스템(Fault tolerant system)을 위해 데이터 블록을 복제한 후 MapReduce를 사용하여 해당 데이터의 계산을 처리한다. HDFS는 기본적으로 128MB 크기의 데이터 블록을 사용하는데 각 블록은 3번 복제된다. 이 블록은 결함이 생긴 데이터의 손실 발생을 막기 위해 존재한다. 또 데이터를 쪼개서 저장하기 때문에 데이터가 128MB보다 커도 저장이 가능하다.
추가 자료 : https://mr-devlife.com/all-about-hdfs-concept/
MapReduce?
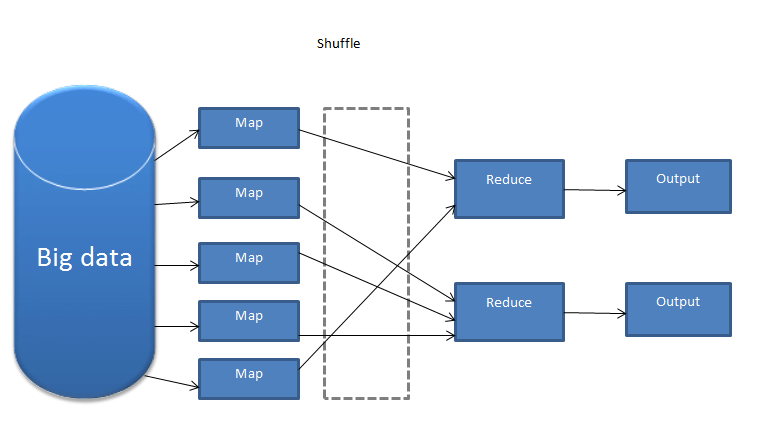
맵리듀스는 computation task (계산작업)을 분산 파일로 분할하는 방법이다. (HDFS 처럼..)
모든 computation을 map과 reduce 두개의 기능(함수)로 표현한다. (map단계가 끝나야 reduce단계를 수행한다.)
Map : 입력 데이터를 분할하여 여러 머신들이 분산 처리하는 함수
Reduce : 이를 다시 하나의 결과로 합치는 함수
또 Job Tracker과 multipe Task Tracker로 이루어져있는데
Job Tracker는 클러스터의 다른 노드들에게 Map과 Reduce의 task를 할당한다. 즉 Job들을 관리하는 역할을 한다. JobTracker이 멈추면 모든 과정들은 중단된다.
multipe Task Tracker는 task에 cpu와 메모리를 할당하고 작업자 node의 작업을 모니터링한다.
Spark?
빅데이터를 빠르고 쉽게 처리하는데 사용되는 최신 기술 중 하나로 Apache의 오픈 소스이다. MapReduce의 대안으로 쓰이는데 spark는 다양한 형식으로 저장된 데이터를 사용할 수 있다. (Cassandra, AWS S3, HDFS 등등..)
MapReduce는 파일을 HDFS에 저장해야 하지만 Spark는 그럴 필요가 없다. 또 MapReduce보다 100배 빠른 처리 속도를 자랑한다. 이는 맵리듀스는 map하고 reduce 작업 후 대부분의 데이터를 디스크에다가 쓰는데(write) spark는 각 변환 후에 대부분의 데이터를 메모리안에 보관(keep)하는데 사용한다.
spark의 주요 핵심은 RDD와 DAG인데,
그 중 RDD를 핵심 장점을 살펴보면
1. 데이터의 분산 수집
2. 내결함성 -분산되어있는 데이터의 에러를 복구할 수 있는 능력
3. 병렬 작업
4. 많은 데이터 소스를 사용할 수 있는 능력
이다.
RDD에서의 연산은 transformation과 action으로 나뉠 수 있는데
transformation은 새로운 인풋데이터로 데이터 셋을 만드는 연산이고 (강의에서는 "기본적으로 따라야 하는 레시피" 로 비유되었다) action은 계산 후 그 결과를 return 하는 것 이다. 즉 Map과 Reduce의 연산을 수행한다고 보면 된다.
또 DAG를 통해 맵리듀스 단점을 보완하여 성능 향상을 하였다.
Dag (Direct acyclic graph) : Data 파이프라인이고 다수의 task로 구성된다. +)방향성이 있고 루프가 없다.
추가 참고 문서 : https://3months.tistory.com/511
해당 강의: https://www.udemy.com/course/best-pyspark-spark-python/
한글 자막 싱크가.. 좀 자연스럽지가 않다 ㅠ 나만 그렇게 느끼는건가..
모르는것 투성이라 좀 더 열심히 공부해야겠다..!